
평가 실행하기
평가 데이터셋이 준비되었으니, 이제 핵심 평가 파이프라인을 구축할 차례입니다. 이 과정에서는 각 테스트 케이스를 가져와 프롬프트와 결합하고, Claude에 전달한 후 결과를 채점합니다.
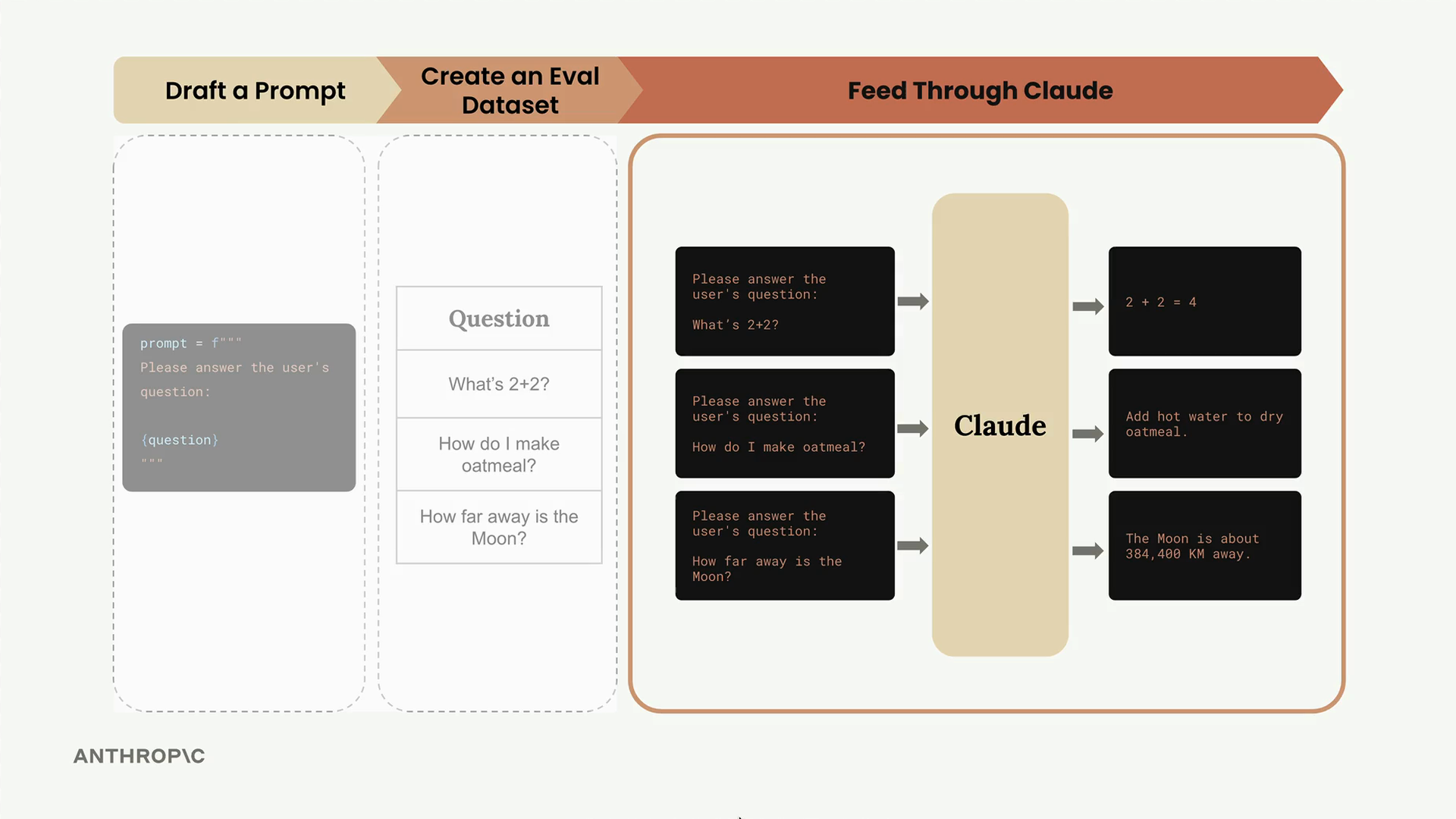
평가 프로세스는 명확한 워크플로우를 따릅니다. 테스트 케이스 데이터셋을 가져와 각각을 프롬프트 템플릿과 결합하고, 처리를 위해 Claude에 전송한 다음, 채점 시스템을 사용하여 출력을 평가합니다.
핵심 함수 구축하기
평가 파이프라인은 각각 특정 역할을 담당하는 세 가지 주요 함수로 구성됩니다. 가장 간단한 것부터 시작해 보겠습니다. 바로 개별 프롬프트를 처리하는 함수입니다.
run_prompt 함수
이 함수는 테스트 케이스를 받아 프롬프트 템플릿과 결합합니다:
def run_prompt(test_case):
"""Merges the prompt and test case input, then returns the result"""
prompt = f"""
Please solve the following task:
{test_case["task"]}
"""
messages = []
add_user_message(messages, prompt)
output = chat(messages)
return output지금은 프롬프트를 극도로 단순하게 유지합니다. 서식 지정 지침을 포함하지 않으므로 Claude는 필요한 것보다 더 자세한 출력을 반환할 가능성이 높습니다. 프롬프트 설계를 반복하면서 나중에 이를 개선할 것입니다.
run_test_case 함수
이 함수는 단일 테스트 케이스 실행과 결과 채점을 조율합니다:
def run_test_case(test_case):
"""Calls run_prompt, then grades the result"""
output = run_prompt(test_case)
# TODO - Grading
score = 10
return {
"output": output,
"test_case": test_case,
"score": score
}지금은 하드코딩된 점수 10을 사용합니다. 채점 로직은 다음 섹션에서 상당한 시간을 할애할 부분이지만, 이 자리 표시자를 통해 전체 파이프라인을 테스트할 수 있습니다.
run_eval 함수
이 함수는 전체 평가 프로세스를 조율합니다:
def run_eval(dataset):
"""Loads the dataset and calls run_test_case with each case"""
results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
return results이 함수는 데이터셋의 모든 테스트 케이스를 처리하고 모든 결과를 단일 목록으로 수집합니다.
평가 실행하기
평가 파이프라인을 실행하려면 데이터셋을 로드하고 함수를 통해 실행합니다:
with open("dataset.json", "r") as f:
dataset = json.load(f)
results = run_eval(dataset)
처음 실행할 때는 시간이 걸릴 수 있습니다. Claude Haiku를 사용하더라도 전체 데이터셋을 처리하는 데 약 30초가 소요될 수 있습니다. 최적화 기법은 나중에 다루겠습니다.
결과 살펴보기
평가는 각 객체가 하나의 테스트 케이스 결과를 나타내는 구조화된 JSON 배열을 반환합니다:
print(json.dumps(results, indent=2))
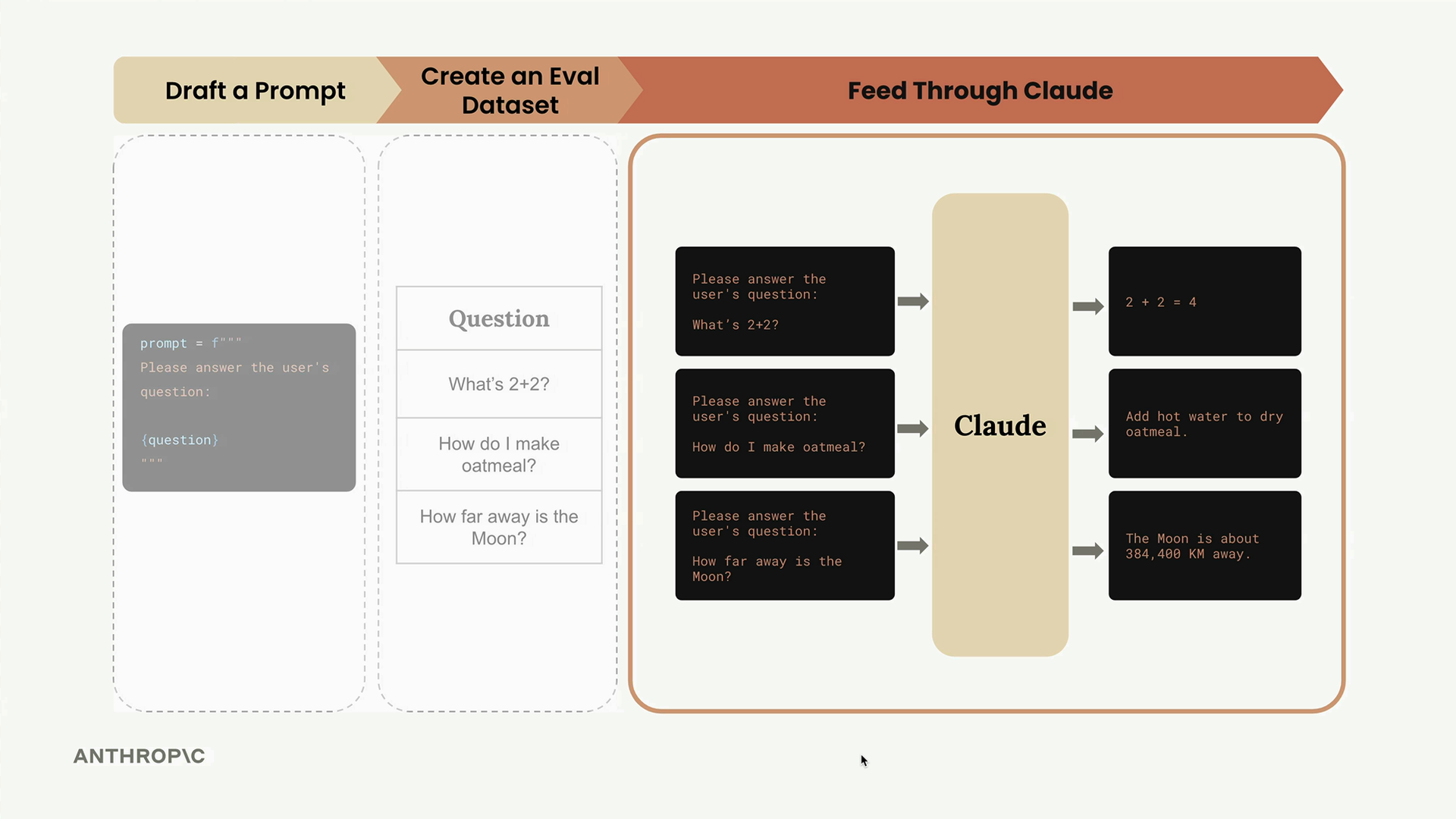
각 결과에는 세 가지 핵심 정보가 포함됩니다:
- output : Claude의 전체 응답
- test_case : 처리된 원본 테스트 케이스
- score : 평가 점수 (현재 하드코딩됨)
출력에서 볼 수 있듯이, 아직 특정 서식 지정 지침을 제공하지 않았기 때문에 Claude는 상당히 장황한 응답을 생성합니다. 이것이 바로 프롬프트를 개선하면서 해결할 문제입니다.
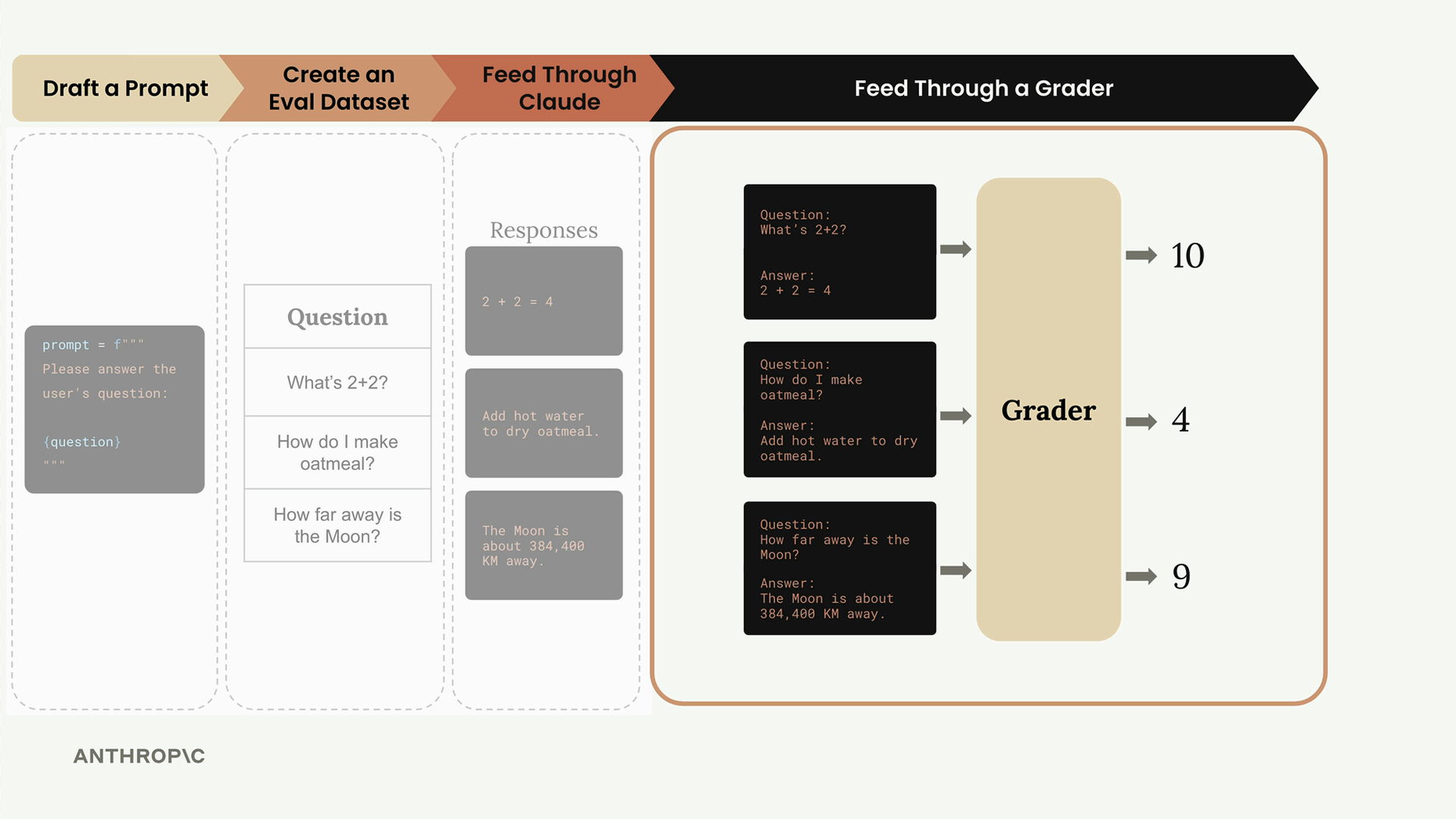
지금까지 달성한 것
이 시점에서 우리는 핵심 평가 파이프라인을 성공적으로 구축했습니다. 데이터셋을 가져와 Claude를 통해 처리하고 구조화된 결과를 수집할 수 있습니다. 아직 부족한 주요 부분은 채점 시스템입니다. 하드코딩된 점수 10을 실제 평가 로직으로 교체해야 합니다.
이 파이프라인은 대부분의 AI 평가 시스템의 기반을 나타냅니다. 단순해 보일 수 있지만, 평가 파이프라인이 실제로 수행하는 작업의 대부분을 방금 구축했습니다. 복잡성은 세부 사항에 있습니다. 더 나은 프롬프트, 정교한 채점, 성능 최적화가 그것입니다.
다음으로, 하드코딩된 점수를 Claude의 성능에 대한 의미 있는 평가로 변환할 채점기라는 중요한 주제를 살펴보겠습니다.